Self-Generated In-Context Examples Improve LLM Agents for Sequential Decision-Making Tasks
Vishnu Sarukkai, Zhiqiang Xie, Kayvon Fatahalian
How can we get language-model-based agents to learn from their own experience?
Much of today’s progress in agent performance comes from scaling: bigger models, more test-time retries, or more human-crafted prompts and demonstrations. But what if an agent could simply watch itself succeed, and get better over time?
This work explores exactly that. By logging its own successful trajectories and selectively reusing them as in-context examples, a base ReAct-style agent steadily improves—achieving up to +20 percentage-point gains across three challenging benchmarks. Crucially, this is done without changing the model, increasing test-time cost, or requiring human input. Just experience.
The Self-Collection Process
When building agents for complex tasks, we often start with little or no task-specific data. Our approach equips a language model (LM)-based agent to collect and curate its own training data over time—relying only on its own experience of success and failure. Below, we define the setting and describe three key stages of our method: Trajectory Bootstrapping (Traj-BS), Database Curation (DB-Cur), and Exemplar Curation (EX-Cur).
Problem Setup
We consider decision-making agents that interact with environments in discrete steps, producing episodes—sequences of observations, actions, and outcomes. A complete episode is called a trajectory, denoted $\tau$, and includes the full trace of reasoning and actions. A trajectory is labeled successful if it solves the given task (e.g., navigates to a goal or produces a correct SQL query).
The agent uses a ReAct-style prompting framework—a standard LLM-based agent design where the model alternates between Thought (reasoning) and Action steps to interact with the environment. At each step, the model is prompted with several in-context examples—short successful trajectories drawn from a database $\mathcal{D}$.
Initially, $\mathcal{D}$ may contain a few human-written examples, or none at all. Let’s call the agent that uses the initial $\mathcal{D}$ Fixed-DB (fixed-database). Our goal is to grow and improve $\mathcal{D}$ automatically, so that the agent becomes increasingly effective over time.
Trajectory Bootstrapping (Traj-BS)
The simplest way to grow $\mathcal{D}$ is to let the agent save what works. After each task attempt, if the episode is successful, we append the full trajectory to the database:
| Input | Process | Effect |
|---|---|---|
| Seed database $\mathcal{D}_0$ (possibly empty) | Run agent → if success, add full trajectory | Positive feedback loop: more wins → better examples → more wins |
This strategy mirrors reward-weighted regression in reinforcement learning: we learn only from successful outcomes, encouraging future actions that resemble past wins. Failure cases are not stored, both to simplify the pipeline and to avoid attribution ambiguity (i.e., which step caused failure?).
Database Curation (DB-Cur)
Early lucky (or unlucky) episodes can disproportionately shape the agent’s long-term performance. To reduce variance, we draw inspiration from population-based training: we run $M$ independent agents in parallel, each maintaining its own version of the database.
After every $K$ tasks (with $K$ doubling over time: 10, 20, 40, …), we:
- Evaluate the recent success rate of each agent–database pair;
- Copy the best-performing database into the worst-performing slot;
- Let all $M$ agents continue collecting trajectories independently.
This strategy prevents poor early seeds from snowballing while preserving valuable structure from high-performing runs (e.g., diverse or complementary examples).
Exemplar Curation (EX-Cur)
Even with DB-Cur, some successful trajectories may be noisy, redundant, or weak. To keep $\mathcal{D}$ compact and high-quality, we compute a value score for each trajectory $\tau$ based on how often it contributes to successful outcomes:
\[Q(\tau)= \frac{\sum_{i\in\mathcal R(\tau)}\mathbf 1_{\text{success}_i}\,f_i(\tau)}{\sum_{i\in\mathcal R(\tau)}f_i(\tau)}\]where:
- $\mathcal R(\tau)$ is the set of tasks that retrieved $\tau$,
- $f_i(\tau)$ counts how often $\tau$ was retrieved in task $i$.
Intuitively, a trajectory that is frequently retrieved in successful tasks earns a high score. For each unique task goal, we retain only the top-1 scoring trajectory, yielding a distilled, high-utility composite database.
This process resembles value estimation in RL: we infer the utility of each trajectory from its downstream effects, prioritizing the most helpful traces and pruning the rest.
Agent Performance Scales with Experience
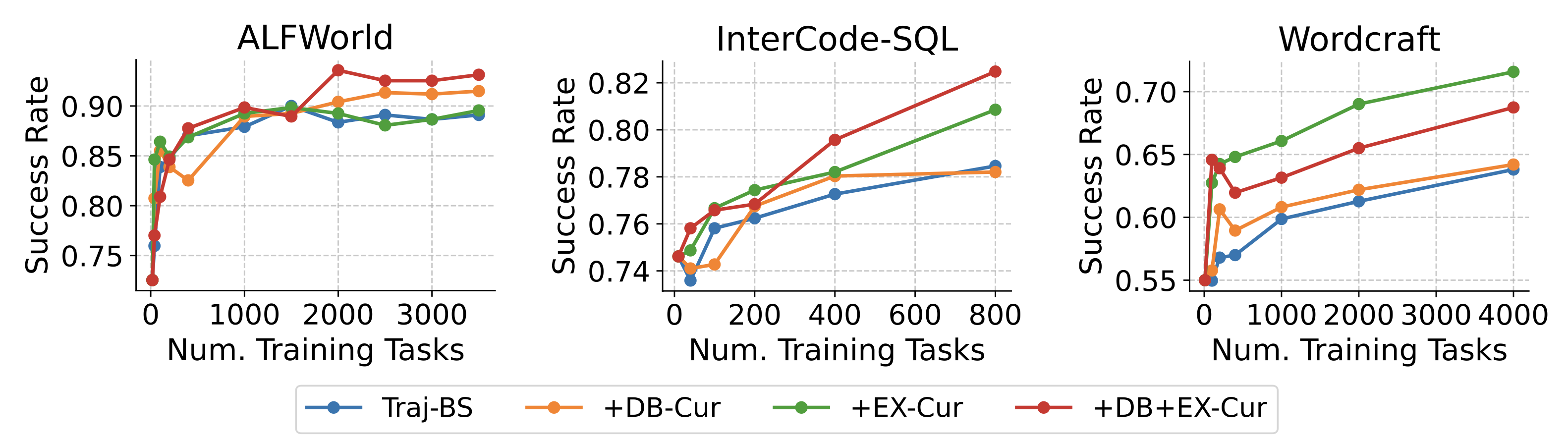
We evaluate our self-improving agent on three benchmark tasks: ALFWorld, Intercode-SQL, and Wordcraft. On all three tasks, agent performance generally improves as the agent self-collects more and more experiences.
Starting from the Fixed-DB (fixed-database) baseline, Traj-BS alone significantly improves success rates across all benchmarks (+16, +4, and +9 percentage points on ALFWorld, InterCode-SQL, and Wordcraft). Database-level curation (+DB-Cur) aims to reduce run-to-run fluctuations, and boosts ALFWorld performance from 0.89 to 0.91. Exemplar-level curation (+EX-Cur) focuses on selecting high-quality individual trajectories, delivering the largest boost on Wordcraft (+8 percentage points, reaching 0.72) and an increase (+2 points) on InterCode-SQL. Combining both curation strategies (+DB-Cur+EX-Cur) can provide complementary benefits, achieving the highest overall performance on ALFWorld (0.93) and InterCode-SQL (0.82). Our two curation strategies independently address distinct limitations—run-to-run variability and individual exemplar quality—and combining them produces the strongest overall agent.
Contextualizing Our Results
We contextualize the effectiveness of our self-curated experience methods on ALFWorld by comparing their performance to alternative scaling strategies: using more test-time computation, upgrading to a larger LLM, and employing task-specific or hierarchical approaches.
| Scaling Axis | Δ Success (pp) |
|---|---|
| Self-curated experience (Traj-BS + DB-Cur + EX-Cur) | +20 |
| Test-time retries (1 → 5 attempts) | +23 |
| Larger model (GPT-4o-mini → GPT-4o) | +15 |
| Task-specific human engineering (AutoManual) | +18 |
-
Comparison with test-time retries: Using multiple test-time attempts is a standard way to boost success rates. Fixed-DB with five independent attempts achieves a +23-point increase on ALFWorld. Our fully-curated self-generated database (+20 points) nearly matches this boost, but critically, it requires only a single inference pass at test time—no extra inference computation or success verification is needed.
-
Comparison with model upgrades: Upgrading the LLM from GPT-4o-mini to GPT-4o delivers a +15-point success-rate improvement. In contrast, our Traj-BS approach provides a greater improvement (+20 points) while maintaining the smaller model, indicating a more compute-efficient scaling route.
-
Comparison with task-specific engineering (AutoManual): AutoManual leverages extensive human engineering of both prompts and task-specific action spaces, achieving a +18-point improvement on ALFWorld. Our fully curated method exceeds this (+20 points) without relying on domain-specific customization, demonstrating that self-curated databases can outperform specialized engineering.
Overall, self-curated experience offers a practical and effective scaling strategy, achieving comparable or superior gains to other methods without incurring substantial additional compute or manual engineering costs.
Implications for Data Curation
High-quality datasets are the cornerstone of effective LLM fine-tuning, yet such datasets rarely exist upfront for new, specialized tasks. Our methods demonstrate that agents themselves can autonomously generate and refine the data they need—not only enhancing their immediate performance through in-context learning but also producing valuable data suitable for subsequent fine-tuning (see Appendix C of our paper). This self-generated data pipeline offers a practical strategy for scaling high-performing LLM agents: rather than relying solely on costly human-curated datasets, agents can bootstrap their own continuous improvement, bridging the initial data gap.