Collage Diffusion
Vishnu Sarukkai, Linden Li, Arden Ma, Chris Ré, and Kayvon Fatahalian
Diffusion models produce beautiful images, but finding just the right prompt and seed to generate the image you want can be a painstakingly long process. This becomes more and more of a problem when trying to generate complex scenes, with many objects in a specific arrangement. When you finally have an image you mostly like, it still isn’t easy to tweak a single object without changing the rest of the image!
Collage Diffusion extends typical diffusion controls–using text prompts, personalizing generation, using ControlNet to preserve edges or pose–to work on individual objects in a scene. With Collage Diffusion, users can create complex scenes in minutes instead of prompt engineering for hours.
Users specify the image they want to generate in three simple steps: 1) upload (or generate) images of each object you want in the scene, with text descriptions 2) drag them to where they belong in the scene, and 3) write a text prompt corresponding to the scene. We call the image of an object paired with its text a layer, and we call the collection of layers along with the overall text prompt a collage. Given a collage, Collage Diffusion generates an image that preserves the arrangement and appearance of the individual objects while making the objects “fit together” in the same image.
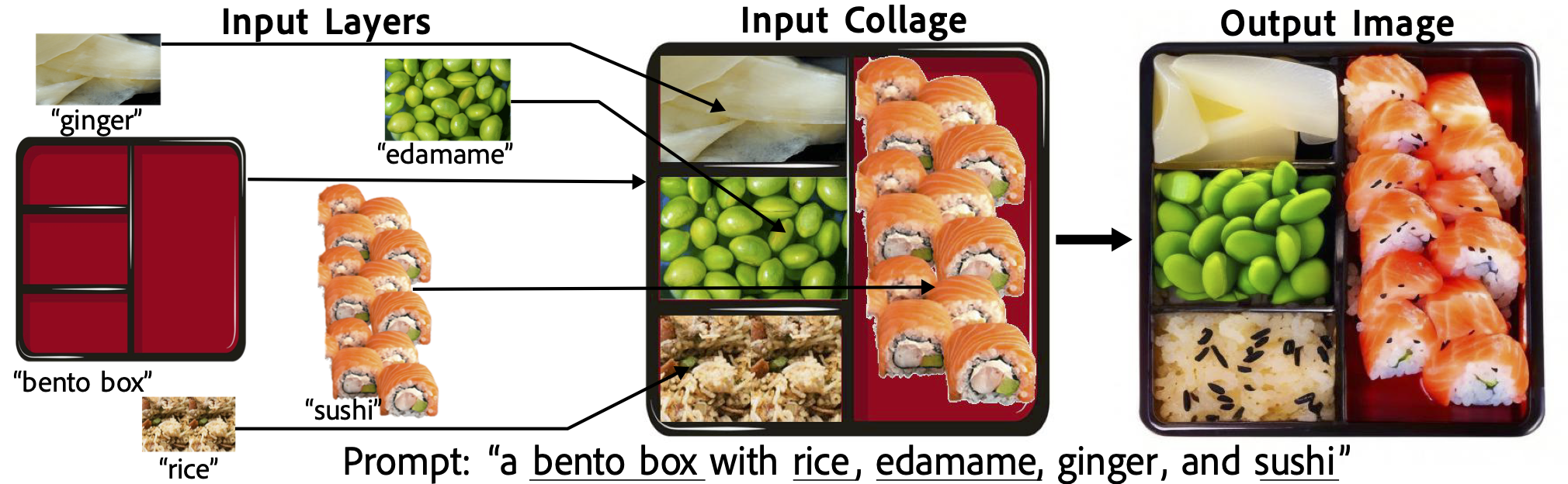

With a layered representation, we can control several aspects of image harmonization on a per-object basis, including spatial layout, the preservation of visual appearance, and the preservation of edge maps. We also gain fine-grained control over the harmonization-fidelity tradeoff on a per-layer basis. Try out our demo here!
How it works
Goal: harmonize, but preserve
We have two main goals when generating images from a sequence of layers:
- Harmonization: the objects in each layer are combined to produce a coherent, self-consistent image
- Fidelity: we preserve key attributes of the input layers. These may include:
- Spatial fidelity: we preserve the spatial arrangement of the objects described by different layers (the sushi is in the right half of the bento box, the ginger in the top left, etc. )
- Appearance fidelity: we preserve key visual characteristics of the objects in the input layers (the sushi is salmon sushi that looks like the sushi in the input layers, the ginger is sliced ginger, not whole ginger, etc.)
- Structural fidelity: we preserve aspects of the image structure of the input layer: edge maps, pose, etc. (preserve the orientation of the sushi in the input layers)
Note that there is an inherent tradeoff between harmonization and fidelity: to make objects fit together in a coherent image, we have to alter them from the initial layer images. First, we introduce algorithmic components to help maintain fidelity to the input collage. Next, we enable user control of the harmonization-fidelity tradeoff on a per-layer basis.
Preserving input layers
One approach to generating a harmonized image from layered input involves constructing an initial composite image from the layers, and then harmonizing with SDEdit. This image-to-image pipeline adds noise to a starting image, then leveraging a learned diffusion model to remove the added noise. The added noise serves to remove details from the starting image while preserving its high-level structure. However, the SDEdit algorithm can’t preserve the scene layout, let alone visual details of the individual layer images:

First, we would like to make sure that for each layer, the object described by the layer text is generated in the corresponding location. We leverage the alpha channels of the layer images to obtain per-layer masks, and extend the Paint-By-Words mechanism from eDiffI to manipulate U-Net cross attention layers to ensure that objects corresponding to each layer text string are generated in the respective locations.

Now, the sushi, ginger, edamame, and rice are generated in the appropriate components of the box, but the sushi and ginger don’t quite look right–the visual content in the input layers has not been preserved.
If there is a particular aspect of the layer’s appearance that we would like to preserve but we cannot capture in text, we aim to preserve that by building upon Textual Inversion, an algorithm for personalizing the images generated by diffusion models. We extend the personalization mechanism from Textual Inversion to work with just a single input image, and apply inversion to the image layers individually.

Now, we have successfully generated an image that has salmon sushi and sliced sushi ginger, similar to the input layers.
When desired, we also have the capacity to preserve structural components of the input layers such as edge maps, pose, etc. ControlNet introduced the capacity to control full-image structure via a variety of conditioning signals: edge maps, human pose, etc. We extend ControlNet to work on individual layers.

Here, we have maintained the edge maps from the initial sequence in the generated image. With per-layer controls, we could instead choose to maintain edges for some objects (ex. the edamame) while allowing them to change for others (ex. the sushi).
Controlling the harmonization-fidelity tradeoff
While we have introduced various methods of improving layer fidelity in the harmonization process, there is a tradeoff between the extent to which layer characteristics are preserved and the extent to which the layers are effectively harmonized. We allow users to control this tradeoff on a per-layer basis by allowing them to specify the level of noise injected in the SDEdit process on a per-layer basis. Our paper contains several images that benefit qualitatively from having control over this tradeoff.
Putting it all together
Layer information makes it way easier to generate images that respect user intent, but what if we still are not satisfied with some part of the generated image? Layers enable iterative edits as well! Let’s take a look at an example: here, a user is trying to generate an image of a scene with two cakes on a table, chairs around the table, a bookshelf in the background, and a window with snowy trees outside. First step is to make a collage:
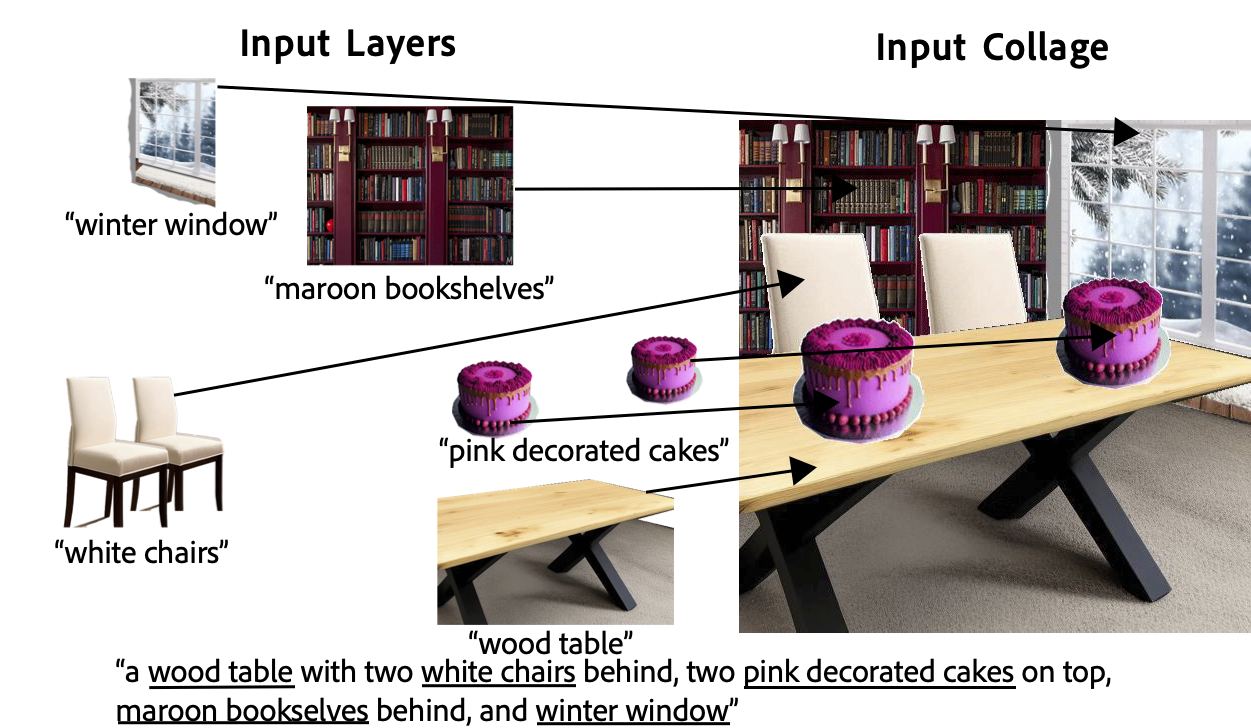
This collage has five different layers, and we will be able to control and edit each of these objects independently. First, we set per-layer noise levels to control harmonization and generates a set of images using Collage Diffusion.
| Option 1 | Option 2 | Option 3 |
|---|---|---|
 |
 |
 |
We like most of the second output image, except for the cake. Leveraging the alpha masks extracted from the input layer images, we can selectively re-generate individual components of an image while keeping the rest constant! We do this by only adding noise to the input layers that we would like to alter:
| Option 1 | Option 2 | Option 3 |
|---|---|---|
 |
 |
 |
We like the cake from the third image! Now, we try out variants of the window in the background:
| Option 1 | Option 2 | Option 3 |
|---|---|---|
 |
 |
 |
The first image matches what we had in mind, and the process is complete!
Links
Posts
-
Building Self-Improving LLM Agents: Paths Toward Lifelong Learning
Blog post authored jointly by Vishnu Sarukkai and Genghan Zhang
-
Diffusion Models and Policy Gradients Share a Common Structure
“True enough, this compass does not point north…It points to the thing you want most in this world.” – Jack Sparrow.
subscribe via RSS